Developers spend most of the time reading and maintaining existing code. We try to understand what it does and how to change or extend it. So why focus only on performance?
Readability should be just as important when building code to last.
When developing long-life software, it’s vital to have great code readability. Be it maintaining the old code, adding new functionality, or changing the old one, readable code makes the job much easier.
Another benefit is when you are in the position of onboarding new developers. Successful onboarding relies on the existing code readability.
The reality is that when you start to work on a product that has been developed for years, you will have to deal with legacy code at some point. A lot of frustration accumulates when you are swamped with thousands of lines of unreadable code that you didn’t write. Maintaining it and building on it only makes that worse.
In Mediatoolkit, we are developing our product long-term. On one hand, that means we avoid short-term fixes and risky business decisions. On the other, it demands the engineering team to put a little extra effort into code readability.
Truth is, we didn’t put as much emphasis on code readability until just a couple of years ago. You guessed it, that was when some serious issues with onboarding new developers and upgrading features arose.
Hopefully, the others won’t repeat our mistakes and will instead start cleaning on time. Here are some guidelines on code readability that we stick to at Mediatoolkit.
Readability is important
If working on an existing product, developers spend most of the time reading and maintaining existing code. If something took years to develop, it’s a given it will take more than a minute to figure out what it does and how to change it.
Despite the amount of time developers spend reading the existing code, more focus is put on writing the new, better performing code. The time needed for maintaining it is rarely taken into account. So, what to focus on instead?
Start with the basics. These are the first steps you can take to improve your code and make it cleaner:
- Use meaningful names
- Improve functions
- Prefer immutability
- Prefer declarative programming to imperative
- Keep it simple stupid – KISS
- Don’t repeat yourself – DRY
- You ain’t gonna need it – YAGNI
Use meaningful names
You name everything in code, so make sure to do it well. Meaningful names provide a context of what is going on. Names should tell the code’s intent – the reason something is there, what it does, and how it is used.
Take your time to come up with good names. Trying to remember what you wanted to express with random gibberish uses up more of your hours.
Code without meaningful names

Code with meaningful names
When possible, names should come from a problem domain. Don’t use technical names if there is a better name in the domain.
Classes and objects should have nouns or noun phrases as their names, such as customer, emailSender, or htmlParser.
But, while following that rule, try to avoid names containing general nouns like data,info, manager, processor, controller …, since those most often do not provide much meaning.
The general term does not tell you what its domain is. It only tells you what it contains in the broadest sense possible.
For example, an object named info is much harder to read than userInfo. Also, you can have multiple infos, controllers, or managers throughout the code, so it is easier to follow the logic of the code when those names are domain distinctive.
Methods should be named using verbs or verb phrases like postPayment, deletePage, or insert. It’s good to avoid using abbreviated names as they are often confusing and intuitive only during the initial development.
Instead, use pronounceable names. Those are easier to understand and memorize while reading and understanding code.
A bad name without comment gives no meaning:

A better self-explaining name:

Pick one term per concept and stick with it
It’s confusing to have fetch, retrieve, and get as equivalent methods of different classes.
Using different names for the same or similar things confuses the reader and opens questions like how these named things differ since they are named differently.
Improve functions
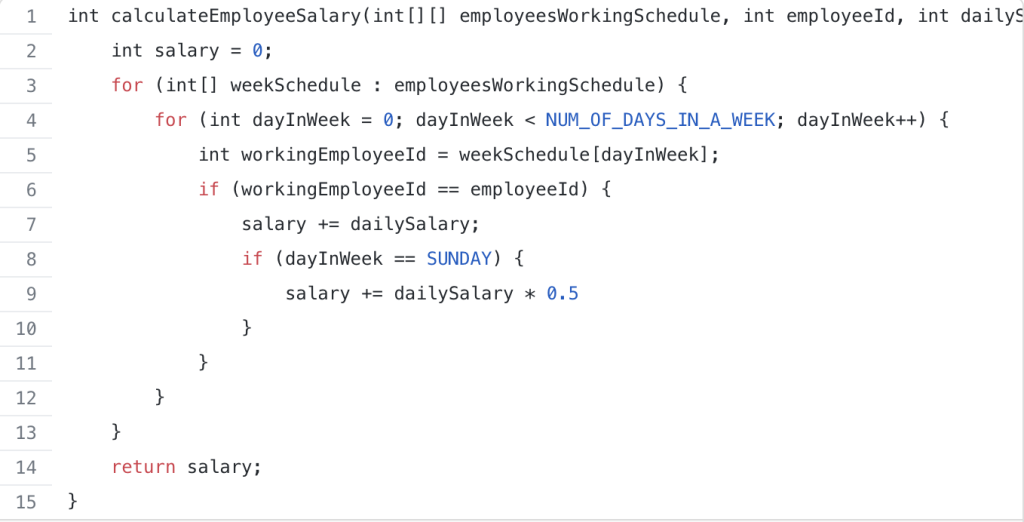
The first thing you can do to improve functions is to make them small. When I say small I mean under 50 lines, preferably under 10-15. By keeping functions small you reduce the context you have to think about while reading.
Indents in functions also increase context keeping. You should have a good explanation of why you have 2 (or more) levels of indentation in a function.
If possible, replace nested indentation blocks with function calls.
A less indented version of `calculateEmployeeSalary` from above:

To improve readability, a function should only do one thing.
Long functions often do multiple things, which makes them long. To do multiple things, while keeping the code readable, you should split long functions into multiple smaller functions.
Function calling other functions should still do just one thing, just a bit more abstract.
Introduce multiple levels of abstraction
Extract snippets of code into functions if you can describe behavior with a higher level of abstraction.
Many higher abstraction level functions are easier to understand compared to a few low-level ones. Abstractions should be based on domain behavior.
Arbitrary abstractions introduced with the purpose of code reuse most often make things worse. Try to keep function calls of a function on the same level of abstraction. That sometimes requires single line functions just to level abstraction which is fine (performance shouldn’t be an issue since modern languages optimize for it by inlining).
Organizing functions hierarchically by levels makes code tell a behavioral story instead of a step-by-step recipe.
Functions should have as few arguments as possible. More than 2 should be seldom used.
Many arguments make code harder to understand, especially when using arguments as output (arguments that are modified after the function completes).
Output arguments are often unexpected and unnatural so avoid them.
NOTE: the previous example uses three arguments to remain as similar as possible with a related example, but should be avoided.
A function should be either a command that performs an action (side effect), or a query that returns data to the caller, but not both.
Their “role” should be emphasized by its name. There should never be a misunderstanding if a function is a command or a query by its name.
Name example of command which modifies its arguments state:

Name example of query which extracts values without modifying arguments state:

Side effects must always be explicit. They should never be unexpected. If unnecessary, avoid them. Try to keep functions “pure”, i.e. stateless.
Prefer immutability
What does “immutability” actually mean in programming?
It’s a property that states that an object/variable cannot be modified after it has been entirely created. Immutable code instead of a mutating state of an object creates a copy with a modified state.
Mutable code:

Same behavior in immutable code:

Immutability makes code simpler and easier to follow.
By knowing an object is immutable, you don’t have to worry if the function to which you are passing the object will modify it. Concurrent programming also becomes easier and cleaner.
Immutable objects are inherently thread-safe, which means there is no need for synchronization blocks since you are always working with an unchangeable consistent state.
Of course, sometimes logic can also be unnatural, complicated, or poor performing, and still expressed as immutable. In that case, you can still use mutability, but try to reduce its scope as much as possible.
Prefer declarative programming to imperative
An important part of writing code your heirs will read easily is choosing declarative programming over imperative. What is imperative and what is declarative programming?
Imperative programming says how to do things. Its focus is on step-by-step mechanics like conditional statements, loops, mutations.
Declarative programming on the other hand says what to do instead of how to do it. Its focus is on what has to be done, meaning whole actions instead of a step-by-step explanation. Declarative programming is built on top of an imperative programming step-by-step style.
Try to abstract imperative code to declarative.
With declarative style, business logic/intent becomes much more obvious. Seeing the intent of the code at first sight makes maintaining and fixing the code much easier to grasp. It enables us to pin-point the problematic part and then dive into the details, as opposed to reading the whole code first just to decipher its intention.
Behavior is more obvious in declarative style as seen below:

Keep it simple stupid – KISS
Developers often come up with “clever” solutions for a given problem.
Those solutions, while looking like a god-send in given moments, shouldn’t be preferred, despite the ego boosts they may give us. Most of the time they are hard to understand and follow, and by that, even harder to maintain or upgrade.
Simplicity should be a key goal in design. Avoid unnecessary complexity.
Don’t repeat yourself – DRY
Duplication is bad, especially duplication of knowledge. You should aim to have a single representation of knowledge in your system. If knowledge changes, you have to change it in each place it is duplicated.
If you miss a duplicate, there’s a good chance it will turn into a bug.
Maintenance easily becomes a nightmare with a lot of duplicates.
It’s a regular practice to copy-paste while prototyping when working on a complex problem. There’s nothing wrong with that, as it helps us spot proper knowledge abstractions, which leads to expressing the intent better.
But, just like we were taught as children, after playtime, it’s time to clean up. Those duplicates served their purpose. Now it’s time to remove them.
You ain’t gonna need it – YAGNI
Do not implement something you “may” need in the future, implement only what you need. What we “may” need very often is not something that we later actually need.
Premature implementation of things we “may” need closes many paths in which our design could go. It forces us with a design not optimized for our product’s real needs, which in turn leads us to a poor(er) and complex(er) overall design which is hard to maintain.
Next steps
The next steps which you can take to improve are SOLID principles.
They are five design principles intended to make software designs even more understandable, flexible, and maintainable:
- Single responsibility principle – SRP
- Open-closed principle – OCP
- Liskov’s substitution principle – LSP
- Interface segregation principle – ISP
- Dependency inversion principle – DIP
By following those (among a few other) principles, we have managed to keep most of the code and domain design readable, easily maintainable, and upgradeable.
The reason we did that is to prepare for welcoming new members of our team, primarily by making the onboarding process more efficient and as comfortable as possible.
Speaking of new members, check out our open position for Senior Java Developer or any other vacancies on our Careers page.